
38 Convert Iso 8859 1 To Utf 8 Javascript Modern Javascript Blog
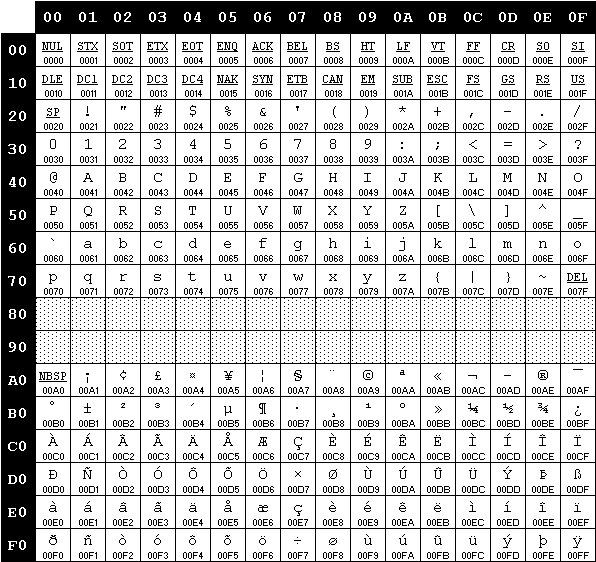
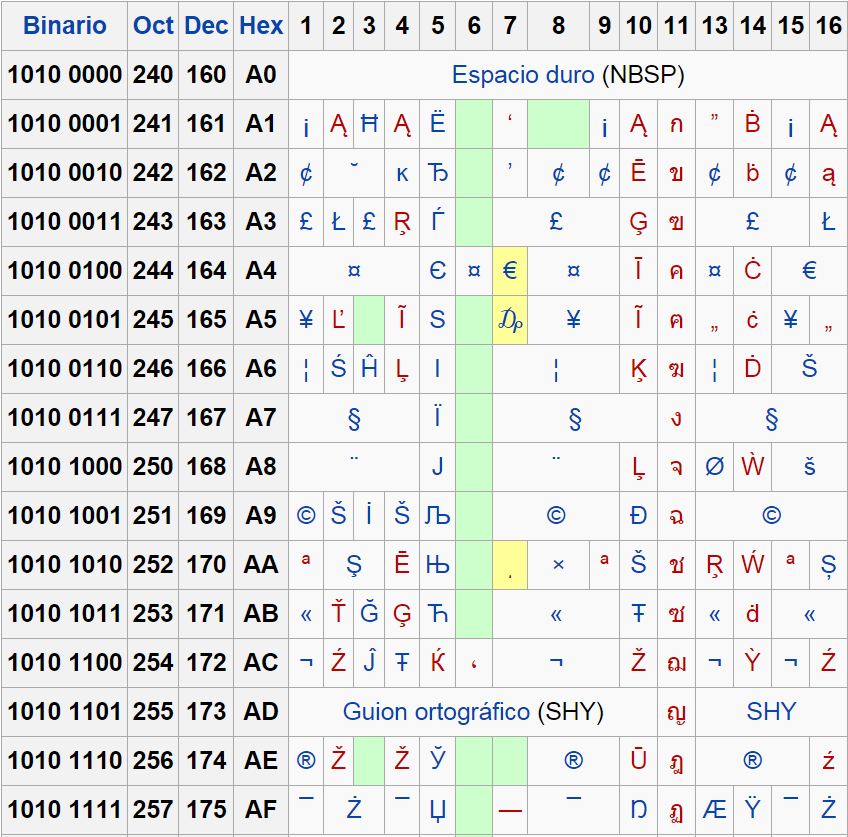
ISO-8859-1 (Western Europe) is a 8-bit single-byte coded character set. Also known as ISO Latin 1 . The first 128 characters are identical to UTF-8 (and UTF-16). This code page has control characters in the 0000-001F and 007F-00A0 range, some are widely used: Many others control characters are now obsolete (these were previously used for.

UTF8,ISO88591,GBK等字符集说明CSDN博客
With UTF-8 you have increased flexibility over ISO 8859-1. The former can encode any character included in Unicode while the latter is limited to Western European languages.. ISO 8859-1 ("Latin1") doesn't include, for example, Greek, Hebrew, Arabic, Cyrillic, Chinese, Japanese and Korean, etc. Share. Improve this answer. Follow answered Jul.

(PDF) UTF8 & Latex Encodings of ISO8859 (Latin1) Character Set
UTF-8 as well as its lesser-used cousins, UTF-16 and UTF-32, are encoding formats for representing Unicode characters as binary data of one or more bytes per character.. One example is Latin-1 (also called ISO-8859-1), which is technically the default for the Hypertext Transfer Protocol (HTTP), per RFC 2616. Windows has its own Latin-1.

Cómo decodificar carácteres en formato UTF8 a ISO88591 Academia Rolosa
ISO-8859-1. ISO-8859-1 was the default character in HTML 4.01. ISO (The International Standards Organization) defines the standard character sets for different alphabets/languages. The different variants of ISO-8859 are listed at the bottom of this page.

killomorning.blogg.se Iso 8859 1 to utf 8 converter
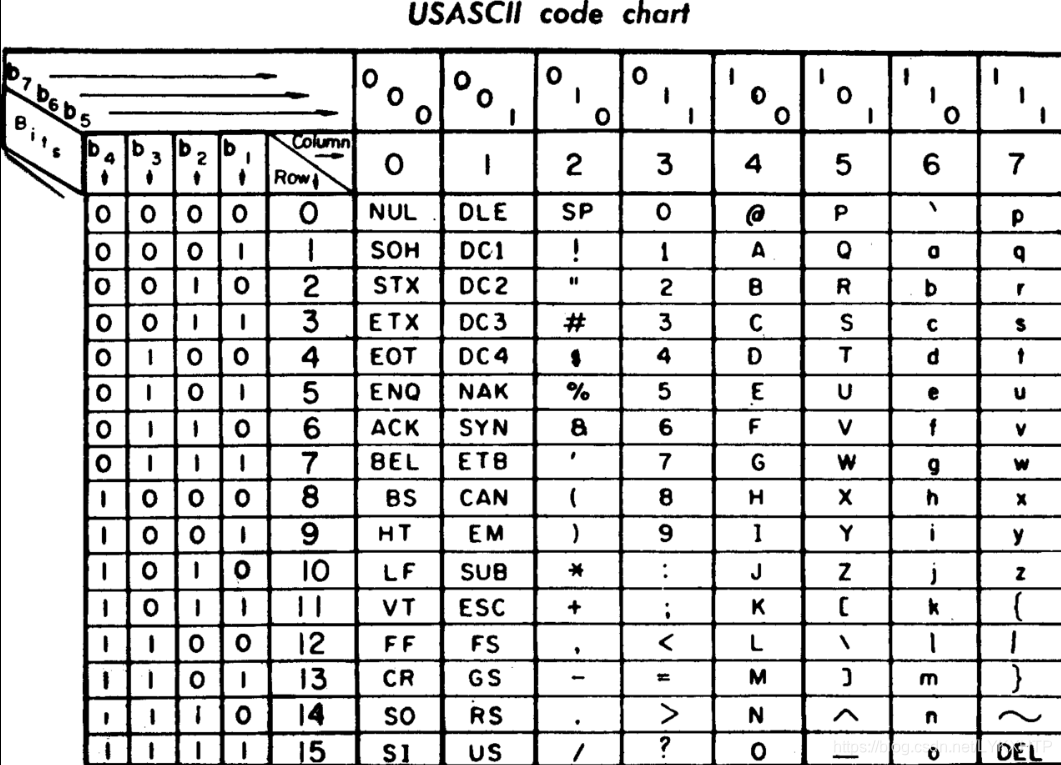
These used to be relatively rarely used, but now many consumer applications will need to be aware of non-BMP characters in order to support emojis. UTF-8: Variable length encoding, 1-4 bytes per code point. ASCII values are encoded as ASCII using 1 byte. UTF-7: Usually used for mail encoding.

Использование UTF8 в HTTP заголовках
ANSWER. For those formats that accept "encoding" as a parameter, you can add this next to the output mime-type with the format "encoding=XXXXXXX". For example, having if the mimetype is "application/json" it would be as below: %dw 2.0. output application/json encoding="ISO-8859-1". ---. {.
Character Encoding Demystified Everything you Need to Know About ASCII, Unicode, UTF8 Borko
Wikipedia explains both reasonably well: UTF-8 vs Latin-1 (ISO-8859-1). Former is a variable-length encoding, latter single-byte fixed length encoding. Latin-1 encodes just the first 256 code points of the Unicode character set, whereas UTF-8 can be used to encode all code points. At physical encoding level, only codepoints 0 - 127 get encoded.
ASCII TO UTF8 converter converts ASCII, ISO88591, Unicode, Western European Character sets etc.
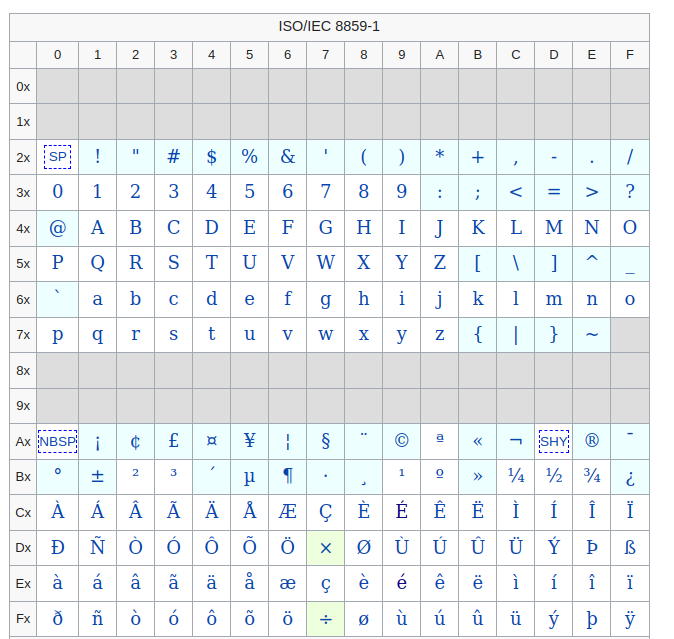
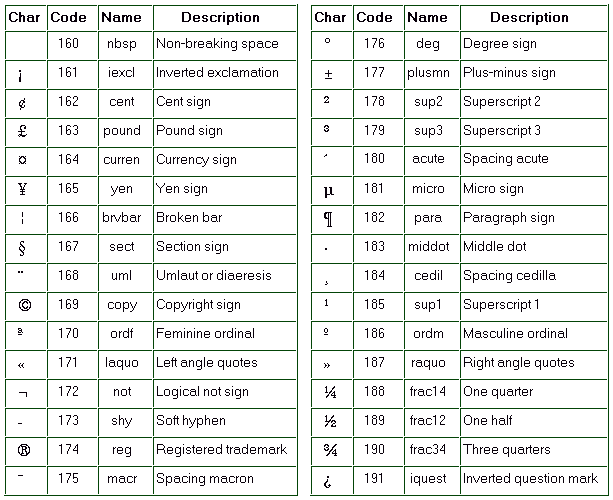
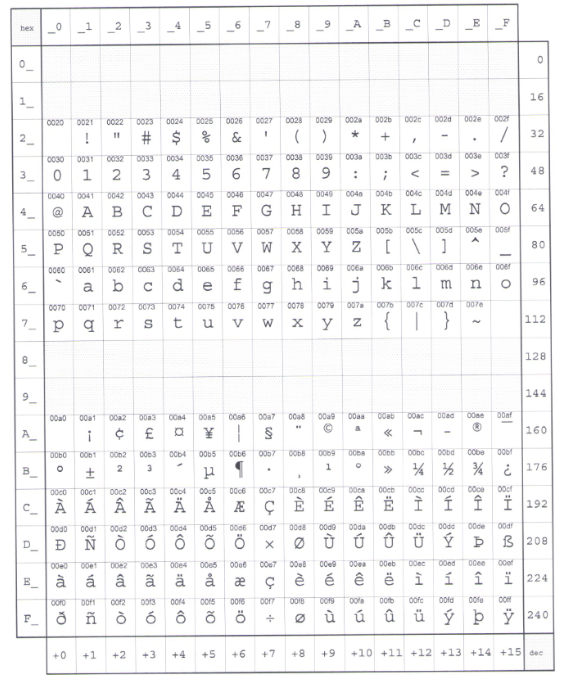
ISO-8859-1 Encoding. ISO-8859-1 is actually a subset of Unicode. It comprises the first 255 Unicode characters (see below for the full character set) and is also sometimes known as Latin-1 since it features most of the characters that are used by Western European languages. (The developer should be aware that the first 127 characters are.
GitHub centauridev/iso88591toutf8
Encoding a text with Western European (ISO) and decoding with Unicode (UTF-8) will sometimes produce strange characters. Characters may display as a box denoting binary data, another character or even several other characters.
Download free software Html Charset Iso 8859 1 Utf 8 fishingbackup
If someone needs this - I think the above commands would do the following: a would take UTF-8's bytes, convert them into ISO bytes and then use a table bytes->chars of ISO encoding to print the string out. In case of string b it would use a table bytes->chars of UTF-8 therefore mapping essencially ISO bytes according to UTF rules.a will be printed out OK even though it's ISO, because Java.
Character sets ISO88591 (Western Europe)
UTF-8 is a multibyte encoding that can represent any Unicode character. ISO 8859-1 is a single-byte encoding that can represent the first 256 Unicode characters. Both encode ASCII exactly the same way. ISO-8859-1 vs UTF-8 ISO-8859-1 is a legacy standard from back in the 1980s. It can only represent 256 characters so only suitable for […]

Unix & Linux Webmin help page encoding iso88591 vs utf8 YouTube
UTF-8 is a variable-length character encoding standard used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode Transformation Format - 8-bit.. UTF-8 is capable of encoding all 1,112,064 valid Unicode code points using one to four one-byte (8-bit) code units. Code points with lower numerical values, which tend to occur more frequently, are encoded.
El juego de caracteres ISO 8859 Programación en
Answer. It's really the local automation system requirements and local needs that determine what encoding format you should use. Most libraries that don't hold a lot of foreign language materials will be perfectly fine with ISO8859-1 ( also called Latin-1 or extended ASCII) encoding format, but if you do have a lot of foreign language materials you should choose UTF-8 since that provides.
ASCII,ISO88591,GBK,Unicode,UTF8 编码介绍
The characters in string is encoded in different manners in ISO-8859-1 and UTF-8. Behind the screen, string is encoded as byte array, where each character is represented by a char sequence. In ISO-8859-1, each character uses one byte; in UTF-8, each character uses multiple bytes (1-4). Here, I would like to show you an excerpt of character.
Curso FrontEnd U1·05 Codificación de caracteres UTF8 vs ISO88591 HTML YouTube
Unicode is backwards compatible with ISO-8859-1 and ASCII. It is a 16 bit scheme and can represent quite a lot of characters and symbols. For English documents, using 16 bit for a character is a little wasteful. The 16 bit scheme requires twice the size needed for ISO-8859-1. To mitigate this issue a UCS transformation called UTF-8 is created.
What is the difference between Western European (ISO) and Unicode (UTF8) character types?
The Universal Coded Character Set ( UCS, Unicode) is a standard set of characters defined by the international standard ISO / IEC 10646, Information technology — Universal Coded Character Set (UCS) (plus amendments to that standard), which is the basis of many character encodings, improving as characters from previously unrepresented typing.
